I am running into an issue when trying to convert a PDF to text where the ligatures 'fi' 'ff' 'fl' are being converted to an empty space. I have read through quite a few similar threads on the issue but have not found a solution that works. This converted text will then be used to match text within a database. So accuracy is paramount. Link to PDF
fp = 'Inspection_redacted.pdf' pdf = pdfplumber.open(fp) fp = fp[:-3] + 'txt' text_file = open(fp, "w") for page in pdf.pages: text = page.extract_text() text_file.write(text) pdf.close() text_file.close() @abokey it would let me post an image initially but here is a mini screenshot of the pdf in question link
Commented Sep 14, 2022 at 21:21 I think you need to share your code so we can reproduce the issue. Commented Sep 14, 2022 at 21:48 @abokey I have attached a link to the PDF as well as my code. Thank you. Commented Sep 15, 2022 at 22:36The problem is not pdfplumber, it is the PDF file that does not fully support text extraction. The ToUnicode cmaps attached to font objects map incorrectly the ligature glyph ids to
Commented Sep 16, 2022 at 11:06pdfplumber seems to not handle ligatures. 'fi' , 'ff' and 'fl' are mapped to '\x00' (empty space) unicode mappings. One workaround is to, first, convert the .pdf to an image with pdf2image library then use an OCR tool (e.g, Python-tesseract ) to recognize the text embedded in images from the .pdf .
To achieve that, you need to :
Make sure to unzip poppler-0.68.0_x86.7z in C:\Program Files.
After installing all the requirements needed, you can run the code below :
from pdf2image import convert_from_path from pytesseract import pytesseract import os pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract' fp = 'Inspection_redacted.pdf' text_file = open(fp[:-3] + 'txt', "w") images = convert_from_path(fp, 500, poppler_path=r'C:\Program Files\poppler-0.68.0\bin') for i, image in enumerate(images): fname = 'image'+str(i)+'.png' image.save(fname, "PNG") text = pytesseract.image_to_string(fname) text_file.write(text) os.remove(fname) text_file.close() @ 7.2.1 FIREPLACES - FIREPLACES (including Gas/LP firelogs) AND CHIMNEYS: Chimney crown/cap cracked 7.2.2 FIREPLACES - FIREPLACES (including Gas/LP firelogs) AND CHIMNEYS: CHIMNEY SWEEP - Excessive Creosote O 7.2.3 FIREPLACES - FIREPLACES (including Gas/LP firelogs) AND CHIMNEYS: Cracks - in Firebox O 7.2.4 FIREPLACES - FIREPLACES (including Gas/LP firelogs) AND CHIMNEYS: Gaps - Seal © 7.2.5 FIREPLACES - FIREPLACES (including Gas/LP firelogs) AND CHIMNEYS: Chimney-Mortar Joint Gaps See/Read here the text file in its entirety.
answered Sep 15, 2022 at 23:48 37.1k 6 6 gold badges 25 25 silver badges 44 44 bronze badgesSo I would really like to avoid OCR at all costs for some of the reasons K J mentioned. These PDFs have thousands of different text options and it would be impossible to know if OCR would convert them all correctly. If we can't find another way around it then I will mark this as the solution.
Commented Sep 16, 2022 at 15:41TL;DR so busy looking at PDF structure I forgot to test the best simple text extraction see end comments, that this is easiest with pdftotext.
I agree OCR can help to locate suspect ligatures, however it is likely that on its own the output may have as many OCR text errors as 14 ligatures you are trying to remove, thus either file compare both outputs for line by line differences (FC.exe or similar helps) or use the OCR fl fi positions to fix the source/output.
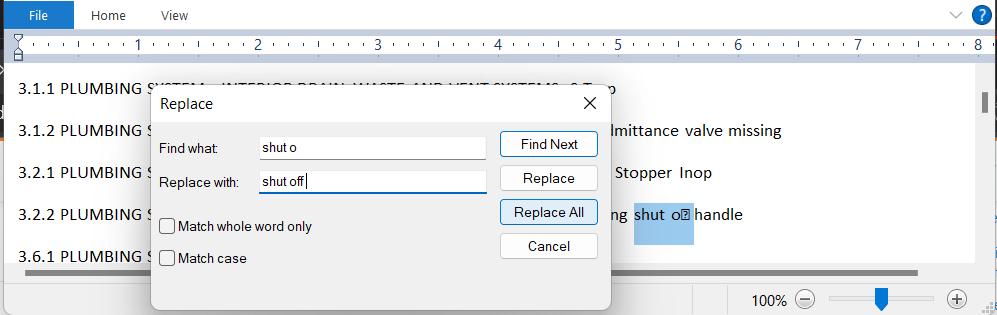
If you accept the plain text at face value it is easy to find and replace 14 known culprits in less groupings by dictionary means thus re would likely be fire not flre nor ffre but is possible it is re on its own thus flag that line context for double checking. If you use an editor you may see where correction is needed so now I see I missed an off in my first pass.
Other FnR's should be simpler so ooring is highly probably flooring and under oor unlikely to be any thing other than underfloor

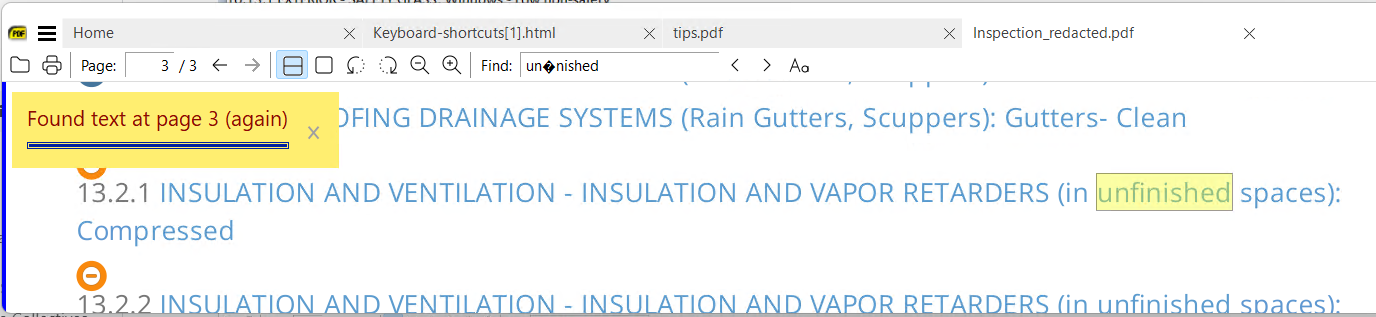
un�nished most likely unfinished (here its easier to see any remaining culprits)

That PDF to text is respected in Xpdf and did it well but most users will have the more permissive poppler utils so remove the find filter and redirect outputs in a loop
pdftotext -enc UTF-8 -nopgbrk -layout "path\file.pdf" will output "path\file.txt"
here testing all 14 previously found
poppler-22.04 >library\bin\pdftotext -enc UTF-8 -layout ligatured.pdf -|find /n "ff" [23] 3.2.2 PLUMBING SYSTEM - FAUCETS, VALVES AND CONNECTED FIXTURES: Missing shut off handle poppler-22.04 >library\bin\pdftotext -enc UTF-8 -layout ligatured.pdf -|find /n "fi" [56]insulation, air filters, registers): *Asbestos Ducts [59] 7.2.1 FIREPLACES - FIREPLACES (including Gas/LP firelogs) AND CHIMNEYS: Chimney crown/cap cracked [61]7.2.2 FIREPLACES - FIREPLACES (including Gas/LP firelogs) AND CHIMNEYS: CHIMNEY SWEEP - Excessive [63] 7.2.3 FIREPLACES - FIREPLACES (including Gas/LP firelogs) AND CHIMNEYS: Cracks - in Firebox [64] 7.2.4 FIREPLACES - FIREPLACES (including Gas/LP firelogs) AND CHIMNEYS: Gaps - Seal [65] 7.2.5 FIREPLACES - FIREPLACES (including Gas/LP firelogs) AND CHIMNEYS: Chimney-Mortar Joint Gaps [81] 11.2.1 ROOF - ROOF COVERINGS (Surface of roofing materials): Limited Life remaining [82] 11.2.2 ROOF - ROOF COVERINGS (Surface of roofing materials): Shingle over Wood Shake [88]13.2.1 INSULATION AND VENTILATION - INSULATION AND VAPOR RETARDERS (in unfinished spaces): [91]13.2.2 INSULATION AND VENTILATION - INSULATION AND VAPOR RETARDERS (in unfinished spaces): [94]13.2.3 INSULATION AND VENTILATION - INSULATION AND VAPOR RETARDERS (in unfinished spaces): [97]13.2.4 INSULATION AND VENTILATION - INSULATION AND VAPOR RETARDERS (in unfinished spaces): poppler-22.04 >library\bin\pdftotext -enc UTF-8 -layout ligatured.pdf -|find /n "fl" [70] 9.2.2 INTERIORS - INTERIORS - General and Visual Mold Assessment : Asbestos - drywall/flooring